LLMs Use Just 16 of 256 Exponents — So We Compressed the Rest Away
2× compression on Llama-3-8B — and perplexity went down.

Search for a command to run...
2× compression on Llama-3-8B — and perplexity went down.
No comments yet. Be the first to comment.
A weight-compression scheme for LLMs that starts where quantization doesn't look - the exponent. SCLP turns the handful of exponent values a model actually uses into a tiny palette, stores the rare outliers exactly, and runs as a fused decode-GEMV kernel on-GPU. This series builds it from the core idea up to 4-bit mixed precision, imatrix-aware sidecars, and the llama.cpp kernels that make it fast on real hardware.
Last time we cut BF16 weights in half by treating the exponent as a 16-entry palette instead of an 8-bit field. SCLP8: 7.9 GB instead of 15.0, perplexity slightly better than the original, token gener
Shipping a 4-Bit LLM Quant into llama.cpp
Last time we cut BF16 weights in half by treating the exponent as a 16-entry palette instead of an 8-bit field. SCLP8: 7.9 GB instead of 15.0, perplexity slightly better than the original, token gener
Make copy of repo git clone dirtySourceRepo newSourceRepo OR clone from actual git repo and prevent push git remote set-url --push origin no_push Make sure to checkout the correct branch before the next step. Cloning from another local directory al...
Most people compressing LLM weights are fighting the same war: squeeze 7 billion floats into less memory without wrecking the model. The standard weapons are quantization schemes — map each float to a small integer, accept some error, move on. INT8, INT4, GPTQ, AWQ, the whole zoo. Different as they look, they all aim at the same target: the mantissa. Reduce precision, round to fewer bits, compensate with per-block scales.
We spent some time looking at the other field instead.
A BF16 float has three fields: 1 sign bit, 8 exponent bits, 7 mantissa bits. The sign is basically a coin flip, so there's nothing to compress there. The mantissa encodes fine-grained precision within a magnitude range, and it's close to random too. The exponent is the odd one out — it determines the order of magnitude, and that's where the structure hides.
So we dumped the exponent distribution of every weight matrix in Llama-3-8B. A typical attention projection has 4096 × 4096 = 16 million weights, each carrying an 8-bit exponent that could in principle take any of 256 values. In practice, 10 to 16 exponent values cover 99.9%+ of every matrix — 14 on OPT-125m's MLP layers, as few as 10 on some attention projections. Calling the distribution "skewed" undersells it; it behaves more like a lookup table.
It's not a quirk of one model either. We checked OPT-125M, Llama-3-8B, and Gemma4-26B and saw the same pattern each time. Training concentrates weights into a narrow magnitude band, and the exponent is what encodes magnitude. The remaining ~0.01% of weights with rare exponents fall into two camps: near-zero (harmless to approximate) or extreme outliers (critical to preserve exactly).
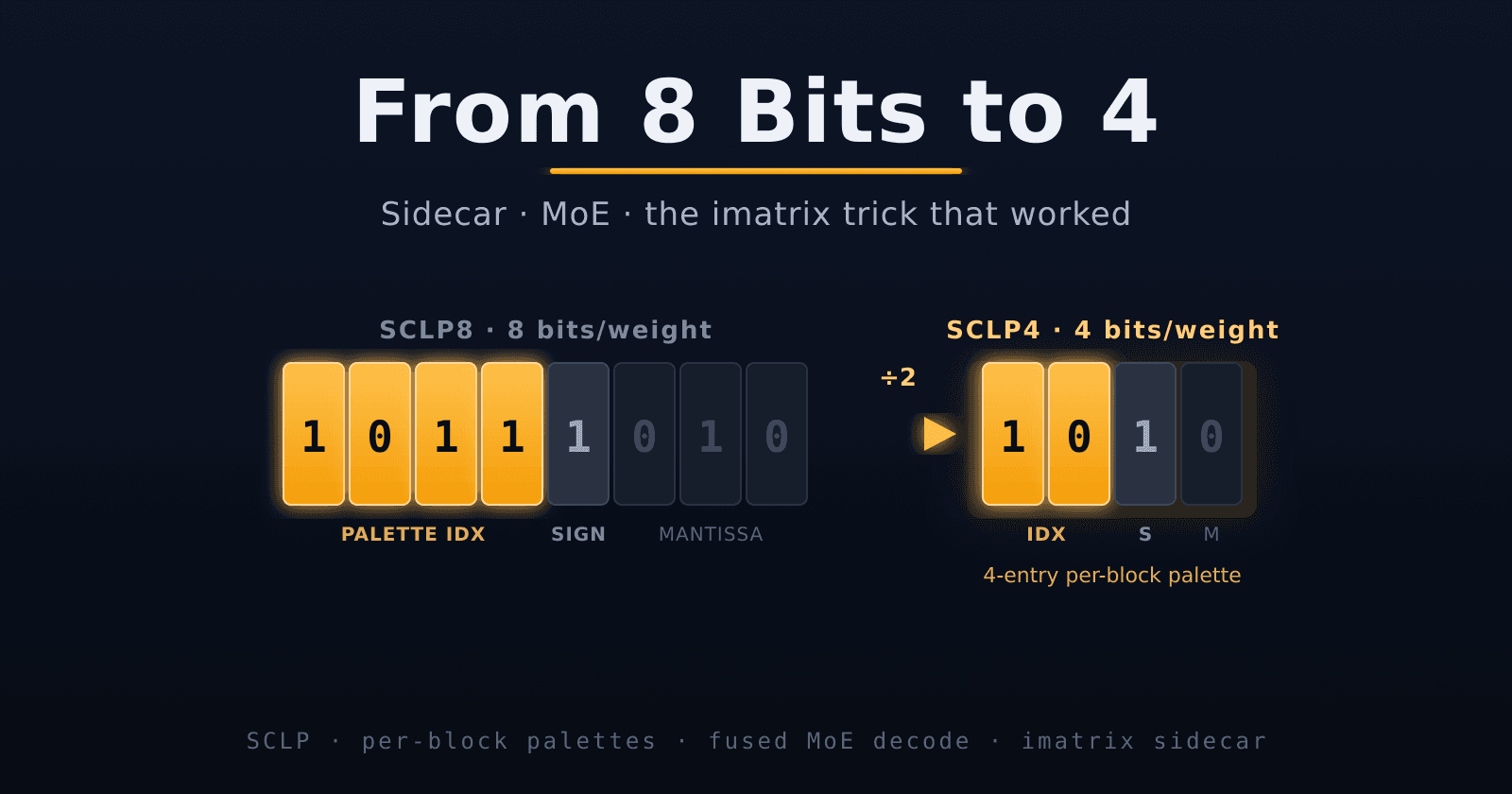
If only 16 exponents matter, you don't need 8 bits to store them — you need 4. Build a palette of the dominant exponent values, store a 4-bit index per weight, and you've cut the exponent from 8 bits to 4 with zero loss for 99.9% of weights.
That leaves 4 bits for everything else, so we pack the sign (1 bit) plus the top 3 mantissa bits (3 bits) into the remaining nibble. One byte per weight.
BF16 weight (16 bits): [sign:1][exponent:8][mantissa:7]
SCLP8 code (8 bits): [palette_idx:4][sign:1][mantissa_top3:3]
Dropping the bottom 4 mantissa bits sounds like it ought to hurt quality, but the effect turned out to be surprisingly mild. It behaves like a form of weight regularization, gently pulling values toward their magnitude's midpoint. On Llama-3-8B the truncation actually lowered perplexity, from 10.59 (full BF16) to 9.87 — which wasn't the result we'd bet on going in.
The 0.01% of weights whose exponents fall outside the top-16 palette could just be mapped to the nearest palette entry, but that introduces a magnitude error — potentially 2x or 4x off for a 1-2 step exponent mismatch. Most of those weights are tiny enough that it wouldn't matter, but a handful carry disproportionate weight for model quality.
So we don't approximate them at all. Any weight whose exponent isn't in the palette gets stored verbatim — full 16-bit BF16 — in a sidecar section appended to the compressed blob, and a fixup kernel scatter-writes them back into the output at decode time. The net effect is functionally lossless for every weight that matters.
The sidecar typically adds 0.01-0.03% overhead, and you can measure it per tensor to decide whether it's worth the bytes.
The first implementation was pure NumPy. Encode takes a uint16 array of raw BF16 bit patterns — we never convert to float — builds the palette with k-means on the exponent histogram, and packs each weight into one byte. Decode runs the same steps in reverse. The whole thing is about 200 lines and finishes in a few seconds on a CPU.
# The core encoding loop (vectorized)
palette_idx = exp_to_idx[exponents] # 4-bit palette lookup
smn = (signs << 3) | mantissa_top3 # 4-bit sign+mantissa
ws_stream = (palette_idx << 4) | smn # pack into one byte
On top of that we wrote a .sclp file format, a round-trip test suite, and a converter that patches individual tensors into existing GGUF files — all before touching a single GPU kernel. Getting the algorithm right on CPU first, where you can print every intermediate value, saved weeks of debugging down the line.
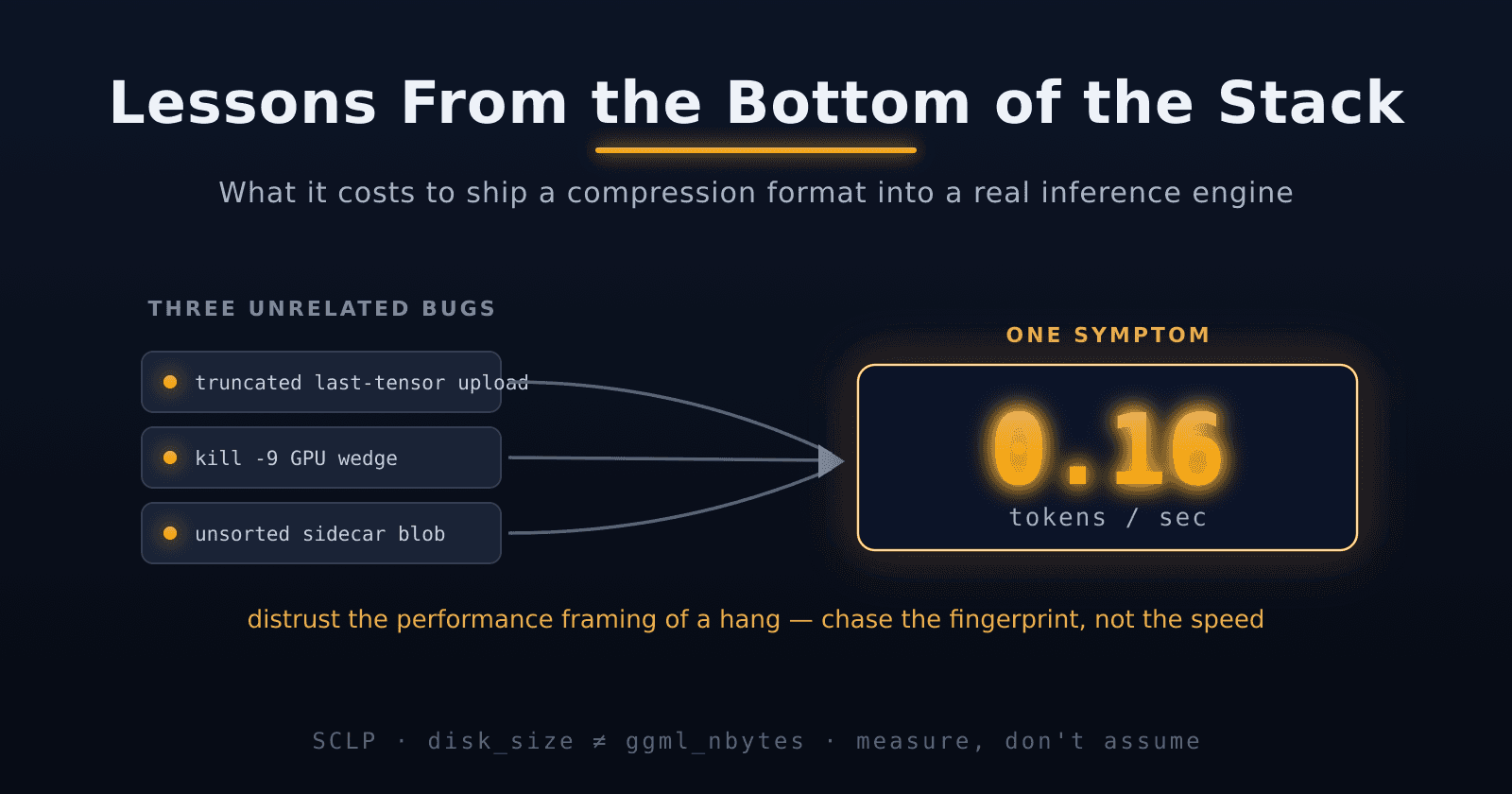
A compression scheme that can't keep up at inference speed is really just a file format. So the target was llama.cpp on an RX 7900 XTX (RDNA3, 24 GB VRAM, HIP/ROCm).
llama.cpp's type system is a set of enums and tables. We added GGML_TYPE_SCLP8 = 47 to ggml.h, registered block size and type size in ggml.c, told the CUDA/HIP backend it can handle SCLP in supports_op, and taught the GGUF loader to infer compressed blob sizes from tensor offsets (since SCLP blobs are smaller than ggml_nbytes would predict).
This plumbing took longer than the compression algorithm did. Every path that touches tensor metadata — allocation, loading, mmap, graph planning — has to agree on what "size" means for a compact blob.
The safe first approach is to decode the entire compressed tensor to BF16 in a GPU kernel, then hand the BF16 buffer to rocBLAS for the matrix multiply. That's two passes over the data, but the decode kernel is simple and the GEMM is battle-tested.
The decode kernel is self-contained: thread 0 reads the blob header (palette size, palette bytes) and broadcasts the palette to shared memory, then all threads decode 8 weights each via coalesced uint64 loads. A second kernel scatter-writes the sidecar values. Both are HIP-graph-safe, with no host-device reads.
This worked on the first try — Llama-3-8B loaded and generated coherent text. But two-pass leaves the headline win on the table: at token-generation time you still read 16 bits per weight (the decoded BF16 buffer) on top of the compressed blob. The bandwidth savings only show up if you never write that BF16 intermediate in the first place.
Two-pass is fine for prefill, where a large matrix multiply means the GEMM dominates. But token generation computes one output row at a time, so the matrix multiply collapses to a dot product — GEMV, not GEMM — and the bottleneck becomes memory bandwidth: how fast can you read the weight matrix?
BF16 reads 16 bits per weight; SCLP reads 8. Decode inline — compute the float value from the palette index and mantissa bits during the dot-product accumulation, without ever writing a BF16 intermediate — and you halve the memory traffic.
That's the fused GEMV kernel. One warp per output row. Each thread reads 8 bytes of compressed weights, decodes them to floats using the palette in shared memory, multiplies by the activation vector (also broadcast to shared memory), and accumulates. The sidecar correction is folded in: because the encoder sorts sidecar entries by weight index, each row can binary-search its contiguous range and apply corrections inline — no atomics, no second kernel.
The result is 43 t/s at 8 bits/weight vs 52 t/s at 16 bits/weight on Llama-3-8B. You read half the bytes but spend more ALU per byte on palette lookup, bit manipulation, and sidecar correction. The trade is a ~7 GB footprint reduction at a modest speed cost. Later optimization — K-tiling for occupancy, compilation unit splitting for register pressure — pushed throughput further on the smaller SCLP types.
Note: an earlier SCLP8 build without sidecar correction showed 66 t/s. Adding folded sidecar (binary search + correction per row) was necessary for quality but cost roughly a third of the throughput. The 43 t/s number reflects the current kernel.
Prefill — processing the entire prompt in one batch — is where SCLP pays its tax. The two-pass path (decode blob → BF16 → rocBLAS GEMM) adds a full weight-matrix read before the GEMM, whereas Q8_0 goes directly through rocBLAS's INT8 path. SCLP8 prefill lands at ~2,650 t/s, against ~3,430 for Q8_0 and ~12,000 for BF16.
We did try fusing the decode into the GEMM, a combined decode+matmul kernel for M > 1. It worked for dense models, but on MoE models the F32 accumulation order between tensor-core tiles and scalar sequential math diverges at ~1e-3 per multiplication. Through 26 MoE layers those differences compound into catastrophic perplexity. Closing the gap would mean exactly replicating rocBLAS's tile accumulation order — doable, but not worth the engineering for a 20% prefill win.
For now the two-pass path is the right default, since prefill isn't the bottleneck for chat and agentic workloads anyway.
SCLP8 on Llama-3-8B comes in at 7.9 GB (vs 15.0 GB BF16), PPL 9.87 (vs 10.59), and 43 t/s token generation on an RX 7900 XTX. That's 2x compression on the weight streams, and the model scores slightly better than the original by perplexity.
But 8 bits per weight is the easy version. The more interesting question is what happens when you push to 6 bits, then 4 — when the palette shrinks from 16 entries to 4, per-block scaling degenerates, and the sidecar population jumps from 0.01% to 5%. That's where mixed precision, per-block palettes, and the imatrix trick that actually worked come in. Next time.
SCLP is open source. The reference implementation (Python + HIP kernels) is at github.com/KerchumA222/sclp. The llama.cpp fork with GPU inference is at github.com/KerchumA222/llama.cpp, branch sclp. Both target AMD RDNA3 (ROCm/HIP) — CUDA porting is straightforward but not yet done.