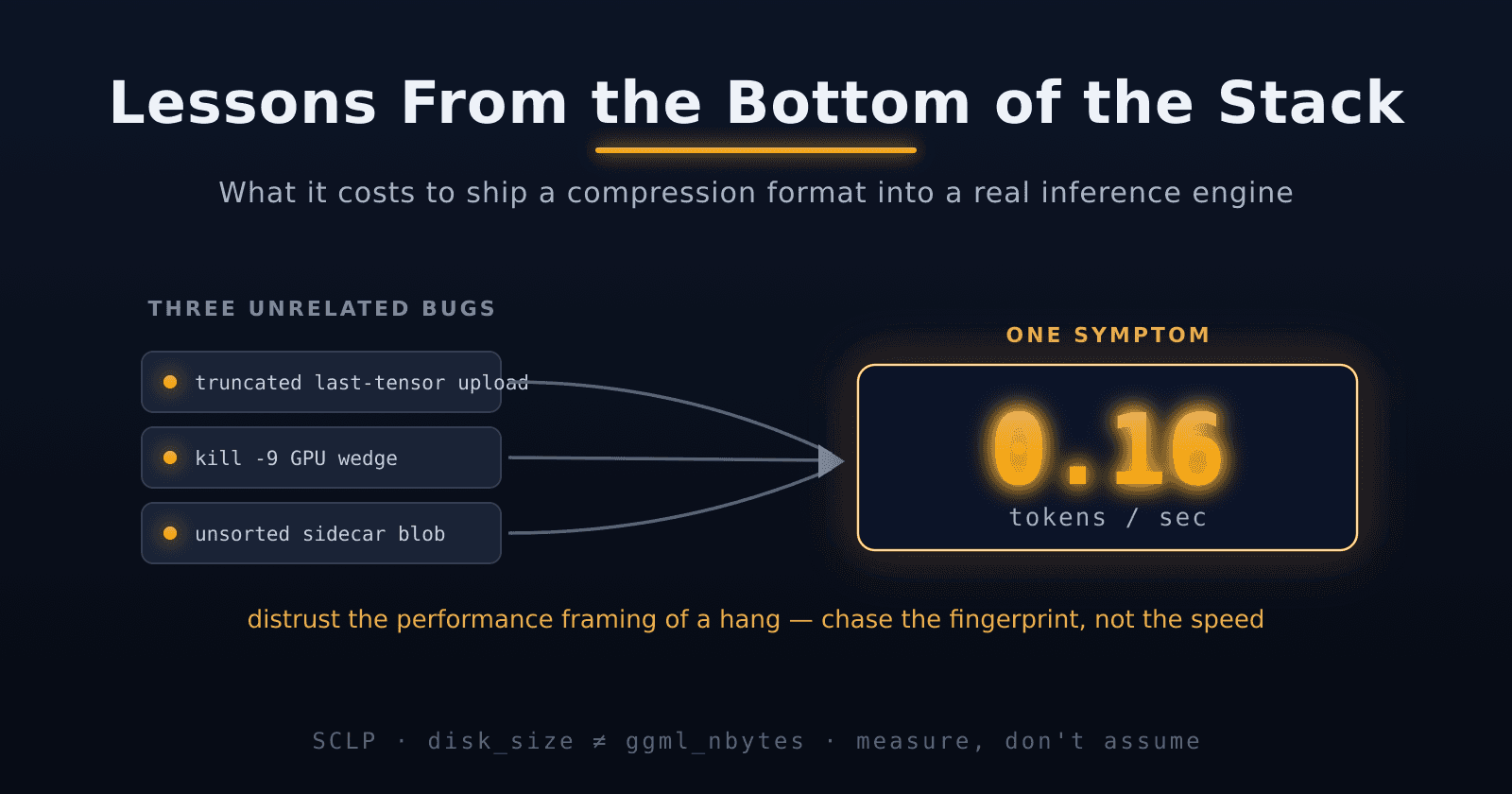
LLMs Use Just 16 of 256 Exponents — So We Compressed the Rest Away
2× compression on Llama-3-8B — and perplexity went down.
May 29, 20269 min read

Search for a command to run...

Series
A weight-compression scheme for LLMs that starts where quantization doesn't look - the exponent. SCLP turns the handful of exponent values a model actually uses into a tiny palette, stores the rare outliers exactly, and runs as a fused decode-GEMV kernel on-GPU. This series builds it from the core idea up to 4-bit mixed precision, imatrix-aware sidecars, and the llama.cpp kernels that make it fast on real hardware.
2× compression on Llama-3-8B — and perplexity went down.
Last time we cut BF16 weights in half by treating the exponent as a 16-entry palette instead of an 8-bit field. SCLP8: 7.9 GB instead of 15.0, perplexity slightly better than the original, token gener
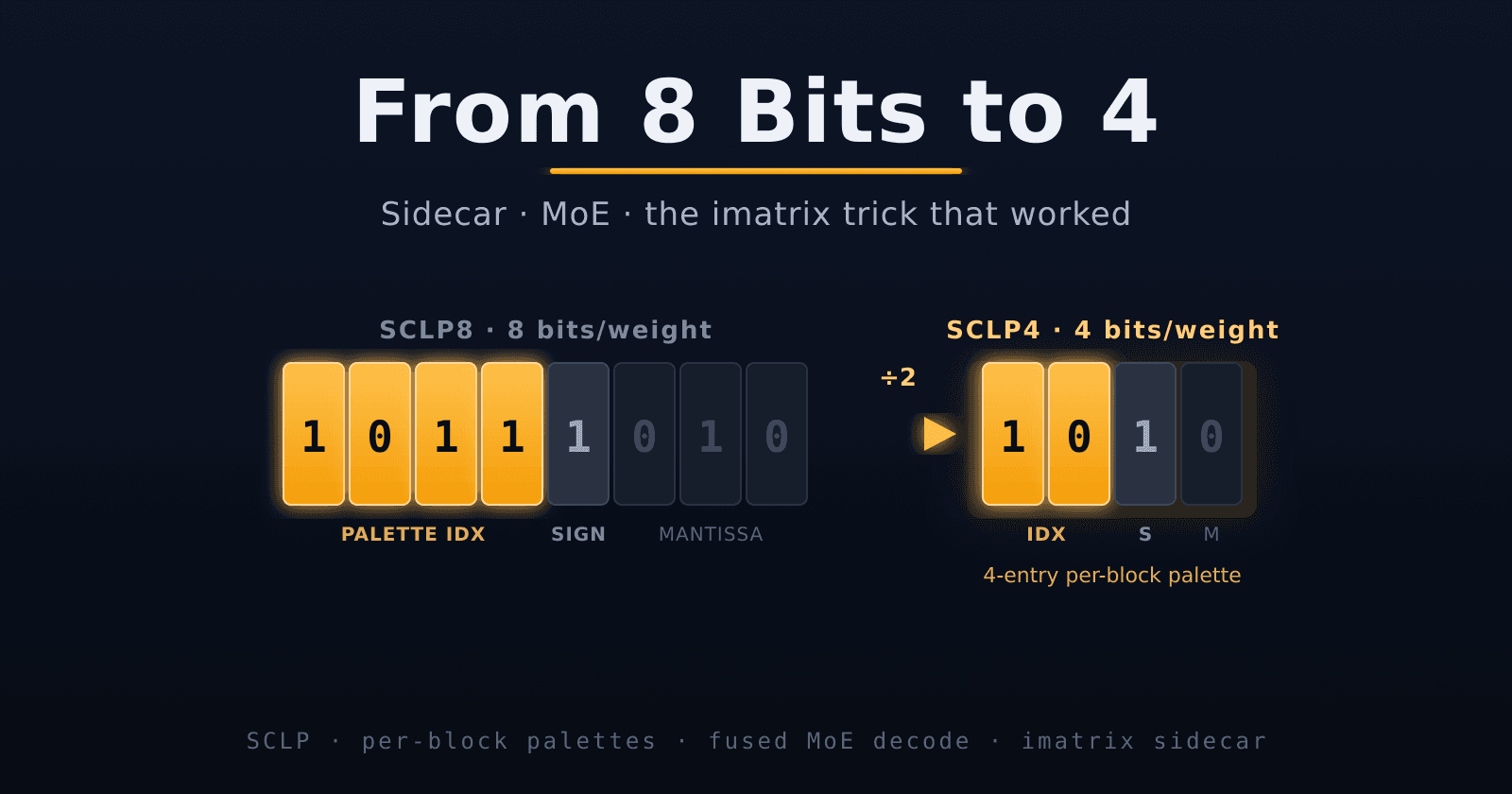
Shipping a 4-Bit LLM Quant into llama.cpp