From 8 Bits to 4: Sidecar, MoE, and the imatrix Trick That Worked
Last time we cut BF16 weights in half by treating the exponent as a 16-entry palette instead of an 8-bit field. SCLP8: 7.9 GB instead of 15.0, perplexity slightly better than the original, token generation at 43 t/s on an RX 7900 XTX.
8 bits per weight is the easy version. Half the bytes, a comfortable palette, a sidecar so small (0.01%) you can ignore it. The real question — the one that decides whether this is a clever trick or an actual competitor to INT4 — is what happens when you keep going. 6 bits. 5. 4.
Everything that was comfortable at 8 bits breaks at 4. Here's the order in which it broke, and what we did about each failure.
The palette runs out of room
The byte budget at each tier:
| Type | Bits | Palette | Mantissa bits |
|---|---|---|---|
| SCLP8 | 8 | 16 entries | 3 |
| SCLP6 | 6 | 8 entries | 2 |
| SCLP5 | 5 | 4 entries | 2 |
| SCLP4 | 4 | 4 entries | 1 |
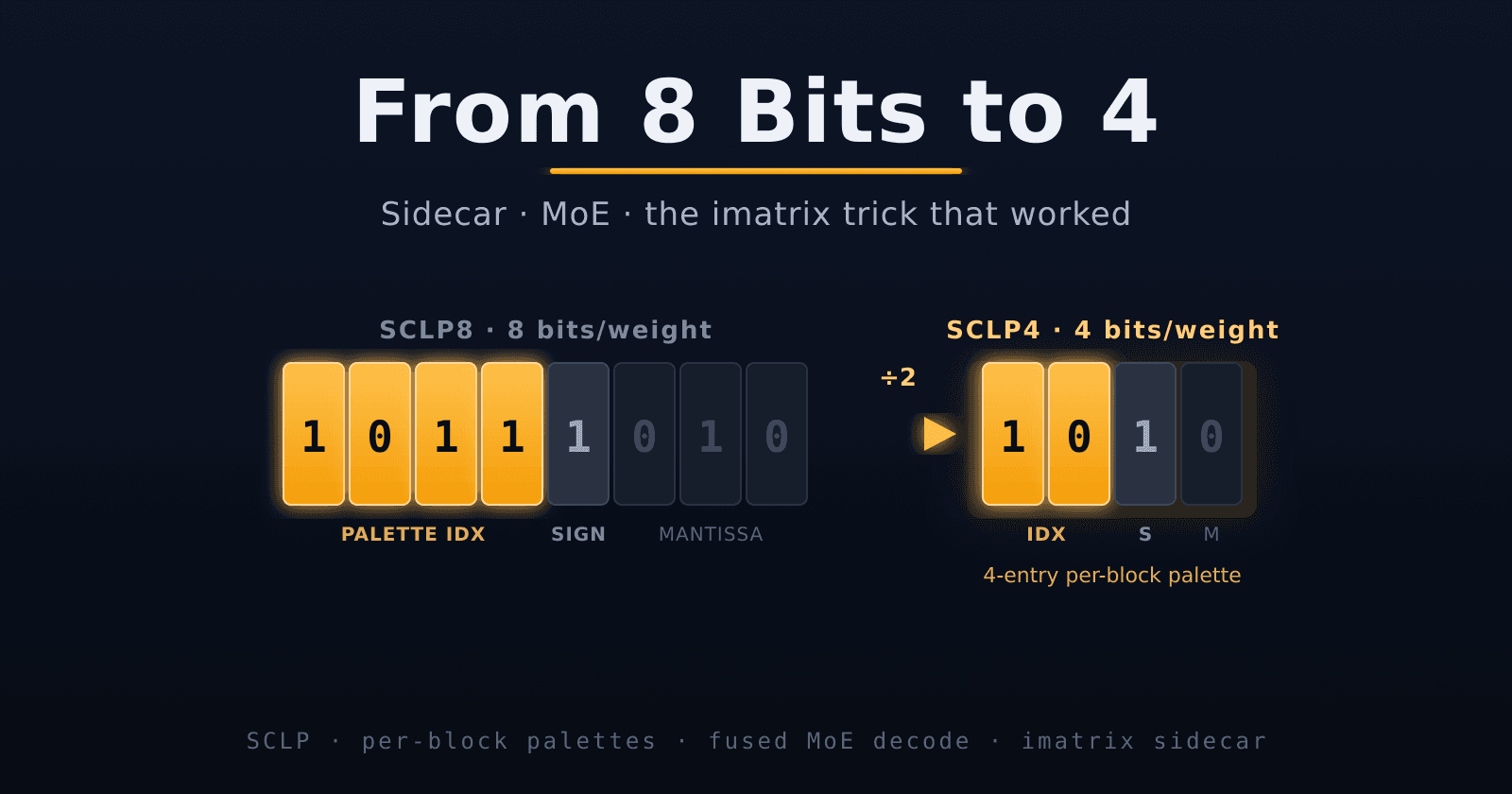
At 8 bits you spend 4 on the palette index and 4 on sign+mantissa. At 4 bits you have to fit everything — index, sign, mantissa — into a single nibble: 2 bits of palette index, 1 sign, 1 mantissa bit. The palette drops from 16 entries to 4.
Four exponent values cannot cover 99.9% of a matrix the way sixteen did. Recall from Post 1 that a typical weight matrix uses 10–16 distinct exponents. Force that down to 4 and you've either thrown away the tails (huge sidecar) or quantized the magnitude itself. Both of those bills come due below.
Per-block scaling, and exactly where it breaks
SCLP6 and SCLP8 carry a per-block scale: one BF16 multiplier per 32 weights. Before encoding, each block is normalized by its max-abs value; the decoder multiplies it back. This costs +6.25% (SCLP8) / +8.3% (SCLP6) and it works — it pulls the weights in a block into a tighter magnitude range so the palette spends its entries where they matter. Gemma4-31B dense and 26B MoE are both coherent with per-block scaling on.
We assumed the same trick would help SCLP4 most of all, since its palette is the most starved. It did the opposite.
Normalizing a block by its max-abs concentrates every weight's exponent up near 126–127. For a 16-entry palette that's fine — you still resolve the spread. For a 4-entry palette it's fatal: all four entries collapse onto nearly the same exponent, and SCLP4 degenerates into roughly 2-bit scalar quantization. On instruction-tuned models the result is unmistakable. Gemma4-26B-IT, pure SCLP4 with per-block scaling, asked anything:
own own own own own own own own own own...
Mode collapse. And here's the part that cost us time: the GPU decode was byte-perfect. We verified it against the CPU reference across all 508 million weights — identical. The garbage wasn't a bug. It was the honest output of a 4-entry palette that scaling had crushed into 2 bits of magnitude resolution. (Llama-3-8B base, same config, doesn't collapse — it stays incoherent-but-diverse. Collapse is an IT-model failure mode, which is its own lesson for the smoke-testing post.)
Per-block palettes
The fix is to stop fighting the local exponent variation and start exploiting it. Instead of one global palette plus a normalizing scale, give each 256-weight block its own 4-entry k-means palette. No scale multiply at all. A block whose weights cluster around exponent 120 gets a palette centered there; its neighbor at 124 gets its own. The same 4 entries that were useless globally become well-placed locally.
The overhead is tiny — 4 palette bytes per 256 weights is 1.56% — and the quality difference is not subtle. Llama-3-8B SCLP4, wikitext perplexity:
| SCLP4 mode | PPL |
|---|---|
| Per-block palette | 102.4 |
| Global palette | 117.6 |
| Per-block scaling (QK=256) | 209 |
Per-block palette is now the only SCLP4 mode. Per-block scaling, the thing that helps every other tier, is the thing you must not do here. SCLP5 (an extra mantissa bit over SCLP4) uses the same per-block-palette structure.
MoE: don't decode what you don't route
Gemma4-26B is a mixture of experts — 128 experts per layer, of which a handful are active per token. The naive integration decoded the entire expert tensor to BF16, then let the router pick. For 128 experts that's a 16× waste of decode work and about 1 GB of scratch VRAM per layer, every token.
So we wrote a fused MoE GEMV: one thread block per (row tile, active expert). It decodes only the routed experts' weights, inline, straight into the dot product — the full BF16 expert buffer never exists. With it, the mixed-precision MoE model runs at the same 55 t/s as the dense path; without it, you pay for 120 experts you never use. Prefill (many tokens) still uses the two-pass decode, since there the GEMM dominates anyway.
The imatrix trick that worked (and the one that didn't)
At 4 bits the sidecar — the verbatim-BF16 escape hatch for weights the palette can't represent — grows from 0.01% to several percent. That's now a real fraction of the file, which means which weights you rescue matters. An importance matrix (imatrix) tells you which weights see the most activation. The obvious move is to weight the palette's k-means by importance so the clustering favors important weights.
We tried that first. It regressed perplexity 5×. Importance-weighting drags palette entries toward high-activation weights and starves everything else, and "everything else" is still most of the matrix.
What worked was applying imatrix to sidecar selection only, never to the palette. Two tiers: a mandatory tier (any weight whose palette distance exceeds a threshold) plus a discretionary tier (the top budget fraction ranked by importance × distance). The palette stays a clean unweighted k-means; the imatrix only decides who gets promoted to lossless storage.
Sweeping the budget on Gemma4 mixed-precision shows a sharp diminishing-returns point — perplexity falls off a cliff as you go from 0 to 1%, then flattens out:
| Sidecar budget | OOD PPL |
|---|---|
| 0% | 13,909 |
| 0.5% | 1,506 |
| 1% | 940 |
| 2% | 1,026 |
1% is the recommended default; 2% is within noise of it — a quality floor, not an improvement. One more trap, and here I'll separate what we measured from what we inherited: ideally you build the imatrix from the BF16 model, not from a Q5_K_M intermediate. An already-quantized model's own rounding noise pollutes the activation statistics the imatrix records, so the importance signal you extract is partly measuring the other quant's errors — which is why llama.cpp quant-makers calibrate against full precision. Where a published BF16-calibrated imatrix was available off the shelf we used one. But the Gemma4 numbers in this section came from a Q5_K_M-sourced imatrix — Gemma4's BF16 is 48 GB and won't fit a 24 GB card — so we never isolated the contamination cost in a controlled same-model run. Treat the size of that effect as community wisdom, not a number from this project. What we did measure is the calibration domain: building the imatrix from in-domain agentic traces instead of wikitext cut SCLP4 sidecar PPL by 32%.
Where 4 bits lands
The headline comparison is against Q4_K, llama.cpp's standard 4-bit integer quant. "MIXED" throughout is one recipe: SCLP6 on the attention projections and ffn_down, SCLP4 on the bulk ffn_gate/ffn_up, embeddings and output kept native — the precision-where-it-matters policy from earlier in this post. The rows differ only in how the SCLP4 portion builds its palette (global vs per-block) and whether imatrix sidecar is applied; the SCLP6 attention/ffn_down half is the same in all three. On held-out agentic traces (OOD perplexity, the number we actually trust):
| Config | Size | OOD PPL |
|---|---|---|
| MIXED, global palette + 1% imatrix | 17.0 GiB | 26.6 |
| MIXED, per-block palette | 14.9 GiB | 132.6 |
| MIXED, per-block palette + wikitext imatrix | 14.9 GiB | 39.2 |
| SCLP6 + Q4_K hybrid | 15.8 GiB | 290.4 |
Per-block-palette SCLP4 beats the Q4_K hybrid by 2.2×, at 0.9 GiB smaller. Global-palette SCLP4 with a generous imatrix budget wins on quality outright — but most of its extra 2 GiB is sidecar, so it's the choice only when size is unconstrained. Q4_K still wins one thing: prefill throughput, because it goes straight through rocBLAS's integer path while SCLP pays the two-pass decode tax (Post 3 has the gory details). For prefill-bound work — long-context RAG — Q4_K gate/up is the right call. For chat and agents, which are decode-bound, SCLP4 is smaller and more accurate.
One thing that surprised us: SCLP4 is the smallest tier but not the fastest at token generation. SCLP4 lands at 34 t/s, behind SCLP6's 38. Fewer bits per weight should mean less to read and faster decode — but an apples-to-apples per-byte comparison of the two decode kernels showed SCLP4's is ~1.7× slower per byte than SCLP6's. The 1-bit mantissa and per-block palette pack more logical work into each byte (more unpacking, more palette indexing per weight), and at these sizes the model already fits comfortably in VRAM, so the bandwidth saving doesn't dominate. Smaller isn't automatically faster — you have to measure the kernel, not count the bits.
One caveat on all of these numbers: wikitext perplexity is inflated roughly 50× out of domain. A healthy Gemma4-IT scores ~50–200 on OOD wikitext that would read as catastrophic if you assumed base-model scales. Use the rankings, not the absolutes — which is exactly the kind of measurement discipline the next post is about.
Where this leaves us
The compression story is, by this point, basically done: SCLP4 at 4 bits/weight, per-block palettes to keep the starved palette useful, a fused MoE GEMV so you only decode what you route, and imatrix-targeted sidecar to spend your lossless budget where it counts. It beats the standard 4-bit integer quant on quality per byte for decode-bound workloads.
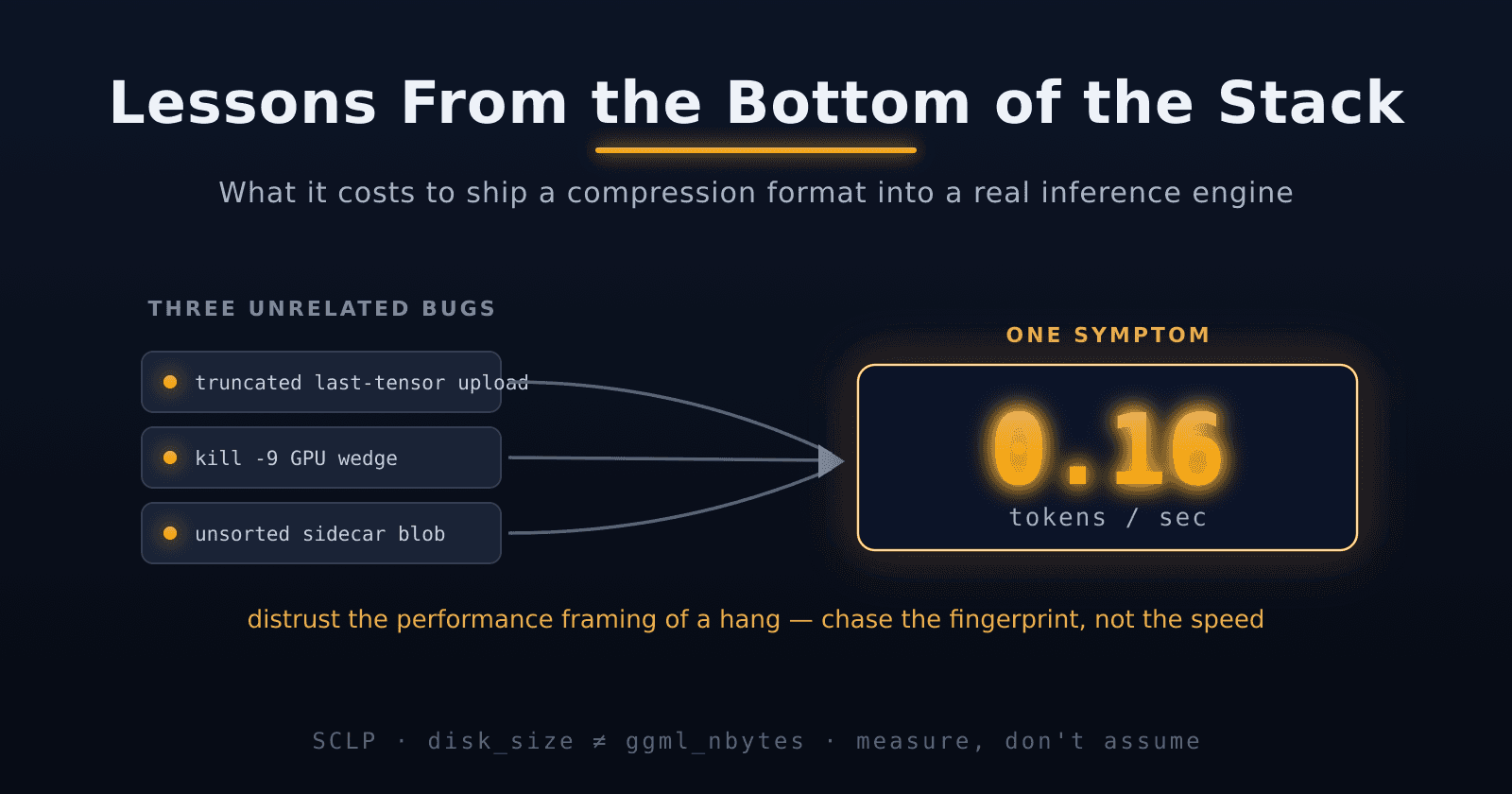
What's left is everything underneath. The algorithm was about a week of prototyping. Making it run — correctly, fast, without wedging the GPU — took the next two, and almost none of it was about compression. That's the last post: the bugs, the dead ends, and the lessons from the bottom of the stack.
SCLP is open source. The reference implementation (Python + HIP kernels) is at github.com/KerchumA222/sclp. The llama.cpp fork with GPU inference is at github.com/KerchumA222/llama.cpp, branch sclp.