Lessons From the Bottom of the Stack: Shipping a Quant
Shipping a 4-Bit LLM Quant into llama.cpp
The SCLP compression algorithm — palette the exponents, sidecar the outliers, pack the rest — was a week or so of prototyping. The two posts before this one covered it end to end. This post is about the other two weeks: getting it to run inside llama.cpp, on real models, fast, without corrupting output or wedging the GPU. Almost none of that work was about compression. It was about the stack underneath, which is where the time actually goes.
It also ran against a hard wall the whole time: a single 24 GB consumer GPU. That ceiling is why so much of what follows is about bytes — VRAM allocation that has to be exact, MoE temp buffers you can't afford, a last-tensor upload that's a few hundred MB too small. The constraint was real enough that we priced out slotting a second card (a 16 GB Vega64 or RX 6800 from another machine) just to offload a few layers, and watched offloading one layer too many hang the entire desktop for a minute at a time. When you have no headroom, every sizing bug is fatal instead of merely wasteful. Most of the bugs below are sizing bugs.
Here are the lessons, each one learned the hard way.
The metadata plumbing is the real work
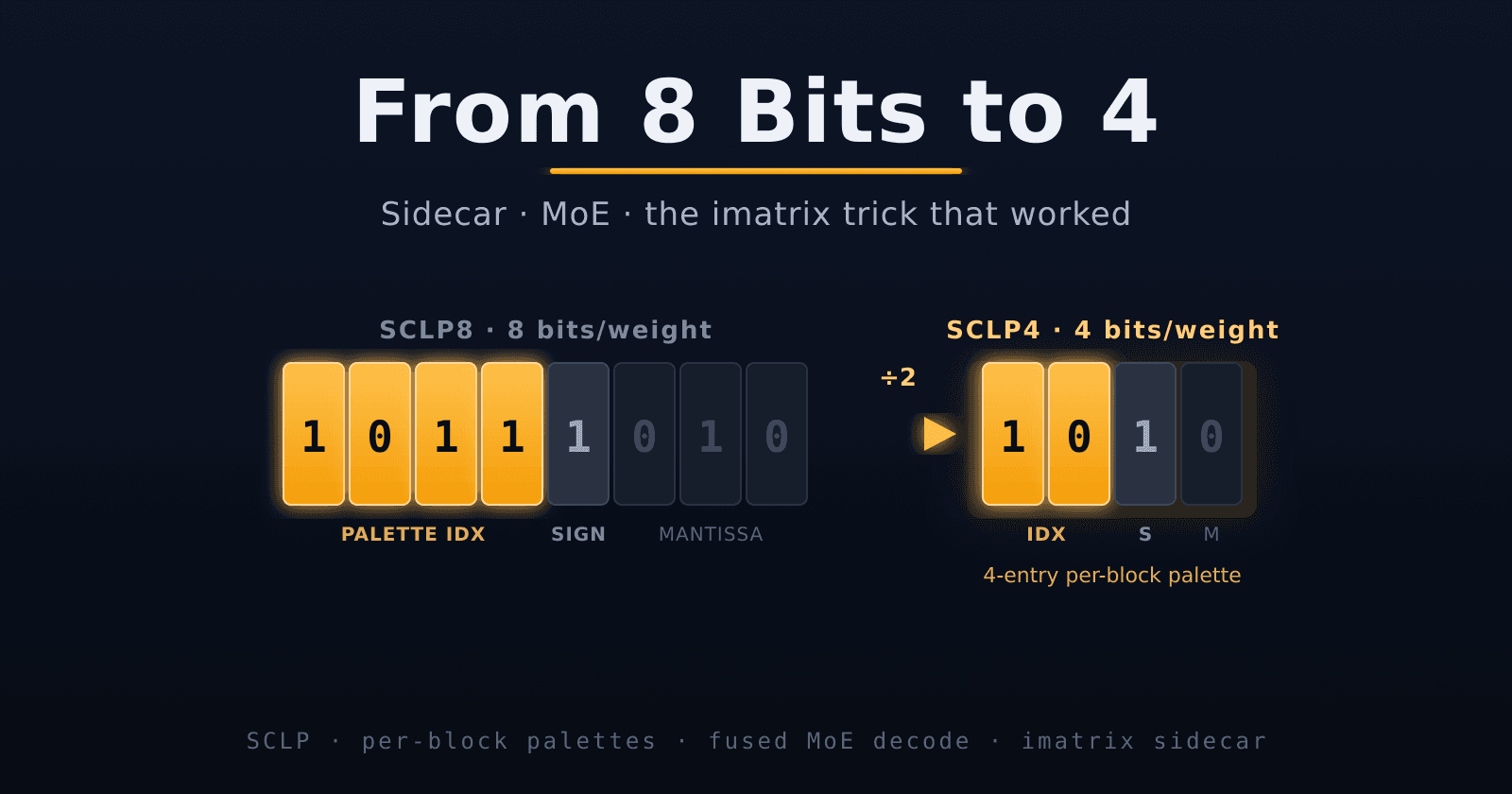
Adding a weight type to llama.cpp sounds like one enum and a decode function. It is not. A tensor's size is computed, checked, and assumed in a dozen places — allocation, mmap, the GGUF loader, graph planning, the VRAM budget. Every one of them assumes size is a closed-form function of shape and type (ggml_nbytes). An SCLP blob is none of those things: it's stored at its actual compressed size, which depends on how many outliers landed in the sidecar, which depends on the weights.
So the loader has to infer each blob's real size — its disk_size — from the gap between consecutive tensor offsets in the file, and thread that number through every path that previously trusted ggml_nbytes. That single concept (disk_size ≠ nbytes) touched four files and was the source of the worst bug in the project. Plumbing a new idea about size through a codebase that has one hardcoded everywhere is the actual work. The compression was the easy part.
The week-long bug: a silent size mismatch
SCLP4 prefill stalled. It didn't crash — it stalled, dropping to 0.16 t/s with the GPU pinned but making no progress. llama-bench hung the same way. Single token generation was fine; only the many-token path died.
The chain: the VRAM allocator reserves space per tensor using disk_size. The last tensor in the file has no "next offset" to subtract from, so its size fell back to ggml_nbytes — which is smaller than the compact SCLP blob. The upload was silently truncated. The GPU didn't crash; it just ground forever on bogus work.
Three things made this expensive to find. It only fired at M > 1 (prefill), because token generation used a different code path. The symptom was a hang, not an error — nothing logged, nothing threw. And the most promising clue was a trap: profiling showed a 430,940,160-byte (~411 MB) host-to-device transfer right at the stall, and that number matched the Q6_K output.weight buffer exactly. It looked like the smoking gun — until we noticed SCLP6 issued the identical 411 MB transfer and never stalled. The fingerprint was real — that transfer genuinely happened — but it pointed at the wrong tensor: output.weight wasn't what stalled us.
What had actually broken was sizing, in the loader. The missing case was the final tensor: with no next offset available, its inferred on-disk size used the old ggml_nbytes fallback instead of the real file span. The decode kernel then read past the truncated upload, picked up a garbage sidecar_count, and scatter-wrote phantom corrections forever. The fix is one line: derive the last tensor's size from the file boundary (file_size − data_offset − tensor_offset) instead of falling back to ggml_nbytes. Finding it took several days of bisecting which tensor, which batch size, which kernel — and learning to distrust the one number that looked like an answer.
The takeaway: a silent size mismatch doesn't crash, it corrupts — and corruption that happens to spin the GPU looks exactly like a performance problem until you stop trusting that framing.
Trust measurements over assumptions
We had three plausible optimizations that should have worked by every rule of thumb. All three were measured, and all three were dead ends.
- F16 decode intermediate. The idea was to decode SCLP to F16 instead of BF16 for the two-pass prefill, on the theory that more mantissa would make the GEMM happier. It measured identical to BF16 on RDNA3, because the GEMM is memory-bound at these shapes and the mantissa bits don't move the needle. We won't retry it.
- hipBLASLt. The newer BLAS path is supposed to be faster. On this hardware it came in at −4% on dense and −31% on the SCLP MoE GEMM — decisively slower, so we left it off.
- Fusing decode into the prefill GEMM. The obvious win was to skip the BF16 intermediate at M > 1 too and decode straight into the matmul. It worked on dense models. On MoE it produced catastrophic perplexity — and untangling why took a detour. The first suspect was a real bug: the fused MoE path corrupted every expert bin past the first (
b≥1tiles were garbage), traced to a wrongexpert_offsetsstride after the route-sort. Fixing the stride made the corruption vanish — and revealed the actual wall underneath. With routing correct, the fused result still diverged from the two-pass result by a deterministic amount, and it was pure arithmetic: the F32 accumulation order of a tensor-core tile differs from scalar sequential summation by ~1e-3 per multiply, and across 26 MoE layers that compounds. So there were two failures stacked — a fixable indexing bug hiding an unfixable ordering difference. Matching rocBLAS's exact tile order is possible but not worth a ~20% prefill win.
That made three confident guesses, three measurements, and three reversals. The pattern is the lesson: on a specific GPU, with a specific BLAS, at specific shapes, your intuition about what's faster is a hypothesis, not a fact. Measure before you commit, and write down the dead ends so they stay dead.
(One smaller version of the same lesson: mixing static __shared__ with dynamic extern __shared__ in a HIP kernel caused a 3× regression on RDNA3. Pure-dynamic shared memory fixed it. Nothing warned us; the profiler did.)
Perplexity can hide collapse — smoke-test for it
Post 2's mode-collapse story ("own own own own...") had a sharp edge worth isolating. That model's decode was byte-perfect across 508 million weights, and its perplexity number looked bad but not obviously broken on our OOD scale. Perplexity averages log-likelihood over a corpus; a model that has quietly collapsed into repeating one token can still post a number that looks merely bad rather than broken — especially when, as we found, OOD wikitext perplexity is inflated ~50× and you've trained yourself to read big numbers as normal.
The only thing that reliably caught collapse was generating a couple hundred tokens of actual chat and reading them. So that became a hard gate: no quant is "good" until it has produced 200+ coherent tokens to a real prompt. A perplexity table is necessary but not sufficient — the inexpensive qualitative check is the one that catches the failure the metric hides.
Don't kill -9 on WSL2/ROCm
A practical one that cost real hours. This work ran on WSL2 with ROCm. If you kill -9 a llama process while it's mid-GPU-kernel, the ROCm runtime doesn't clean up — the GPU wedges, and everything afterward drops to ~0.16 t/s (the same number as the truncation bug, which made triage briefly confusing). In our setup, the reliable recovery was wsl --shutdown.
So: bound every GPU job with timeout instead of reaching for kill, and never SIGKILL a process that's touching the device. On WSL2 the GPU isn't a resource the OS will reclaim for you. Treat a wedged GPU as a possible environment state, not only a code bug — we spent time hunting a regression that was really a leftover wedge from a previous kill -9.
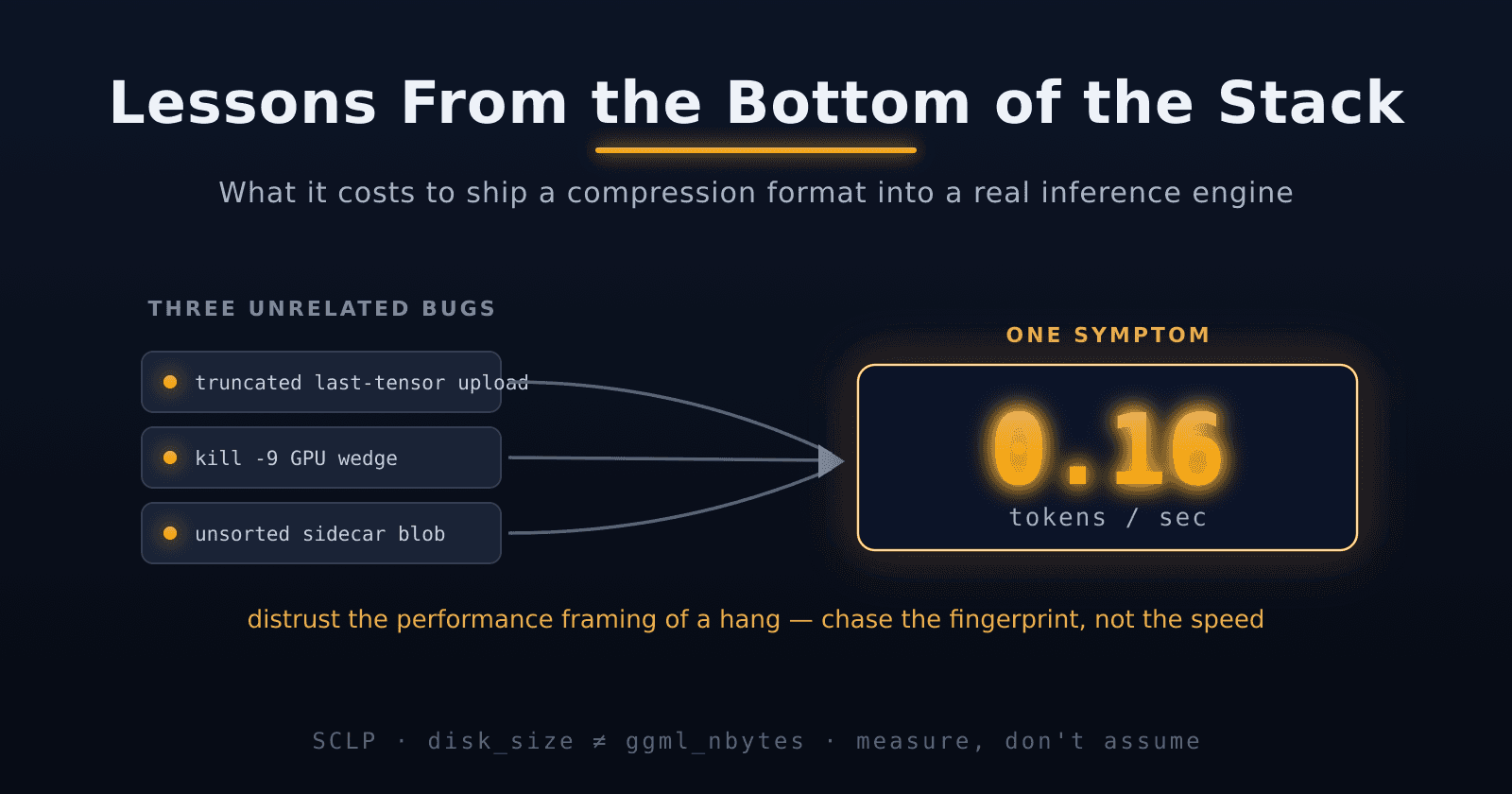
That ~0.16 t/s reading turned out to be badly overloaded: three unrelated failures all produced it: the truncated last-tensor upload, a genuine kill -9 GPU wedge, and — the one that fooled us longest — running the fused GEMV on an old model whose sidecar wasn't sorted. The fused kernel binary-searches each row's sidecar range assuming the entries are sorted by index; on an unsorted blob the search returns a bogus enormous range, and every row grinds through millions of phantom corrections — producing the same 0.16 t/s. We first diagnosed it as a wedge and reached for wsl --shutdown — which of course "fixed" nothing, because the next run loaded the same stale model. The lesson stacks on the truncation one: when three different bugs share a symptom, the symptom tells you almost nothing. You have to find the fingerprint that distinguishes them.
What the bottom of the stack taught us
Step back and the lessons rhyme:
- A new invariant is expensive to introduce. "Size isn't
ggml_nbytesanymore" was one sentence, four files, and the worst bug. - Silent corruption masquerades as slowness. A truncated upload, an unsorted sidecar, and a genuine GPU wedge all produced the same 0.16 t/s — three different bugs, one symptom. Distrust the performance framing of a hang; chase the fingerprint, not the speed.
- Your speed intuitions are hypotheses. F16, hipBLASLt, fused prefill — three "obviously faster" ideas, three losses on measurement.
- The cheap eval is the one you skip and the one that catches the disaster. Byte-perfect decode and a not-even-scary perplexity both passed while the model said "own own own."
- The environment has state. On WSL2/ROCm a kill can outlive its process.
None of this is about exponents or palettes. It's the tax on shipping a format into a mature inference engine on consumer hardware — and it dwarfed the algorithm that started the whole thing. SCLP does what it set out to do: on the models we tuned for, 4-bit weights that match or beat the standard integer quant on quality per byte for decode-bound workloads, running coherently on a sub-$1,000 GPU. Getting there was mostly the work in this post, not the work in the first two. That's usually how it goes.
Postscript: trying it on Gemma 4 12B
While we were writing this post, Google released Gemma 4 12B, so we ran SCLP on it. The hypothesis was modest: perhaps we could compress it a little further than the standard quants, but because a 12B model isn't memory-constrained on a 24 GB card — it fits comfortably even at 8-bit — the bandwidth advantage SCLP relies on probably wouldn't materialize.
It didn't, and the result illustrates this post's running theme cleanly enough to be worth showing in full. Every configuration below was built with an imatrix from in-domain traces; perplexity is measured on a held-out out-of-domain set (lower is better, and as Post 2 noted these OOD numbers run roughly 50× inflated — read the rankings, not the absolutes). Throughput is llama-bench on the RX 7900 XTX, fully offloaded.
| Quant | Size | OOD PPL | Prefill (t/s) | Generation (t/s) |
|---|---|---|---|---|
| Q4_K_M | 6.87 GiB | 55.1 | 1921 | 55.7 |
| SCLP4 | 8.27 GiB | 646.5 | 1815 | 22.5 |
| MIXED-Q4 (SCLP6 attn+down, Q4_K gate/up) | 9.17 GiB | 57.9 | 1981 | 32.5 |
| MIXED (SCLP6 attn+down, SCLP4 gate/up) | 9.51 GiB | 64.9 | 1817 | 23.2 |
| SCLP6 | 10.86 GiB | 57.7 | 1940 | 23.5 |
| Q8_0 | 11.80 GiB | 54.8 | 2134 | 46.1 |
| SCLP8 | 12.70 GiB | 55.0 | 1928 | 26.5 |
Two head-to-heads tell the story. At 8 bits, Q8_0 beats SCLP8 on every axis: it is smaller (it quantizes the embeddings too, which SCLP keeps at BF16), matches perplexity, and generates 1.7× faster. At 4 bits, Q4_K_M is both smaller than SCLP4 and far more accurate — pure SCLP4 puts 4-bit precision on the attention projections, which collapses quality (the same failure mode from Post 2; the MIXED recipe, which protects attention with SCLP6, recovers most of it). SCLP did not even win on size: the imatrix sidecar plus native embeddings push every SCLP build above its standard-quant counterpart.
The reason is the subject of this entire post — measure, don't assume. SCLP's advantage is bandwidth: fewer bytes read per weight at generation time, which converts to speed only when bandwidth is the bottleneck. On a model that fits in VRAM with room to spare, the standard quants' INT8 dp4a GEMV simply runs faster than SCLP's decode-and-multiply kernel, and the extra arithmetic SCLP spends on palette lookups and sidecar corrections is pure overhead rather than a trade against saved memory traffic. The wins in Posts 1 and 2 came from models pushed against the VRAM ceiling — and, for the 4-bit quality-per-byte result, from a mixture-of-experts architecture. Neither condition holds here, and the numbers reflect that precisely.
That is not a disappointing result so much as a sharp one: it marks where SCLP belongs. For a model too large for your card, every byte trimmed from the weight read is bandwidth returned. When the model already fits, the standard quant is the better tool.
SCLP is open source. The reference implementation (Python + HIP kernels) is at github.com/KerchumA222/sclp. The llama.cpp fork with GPU inference is at github.com/KerchumA222/llama.cpp, branch sclp. Both target AMD RDNA3 (ROCm/HIP) — CUDA porting is straightforward but not yet done.