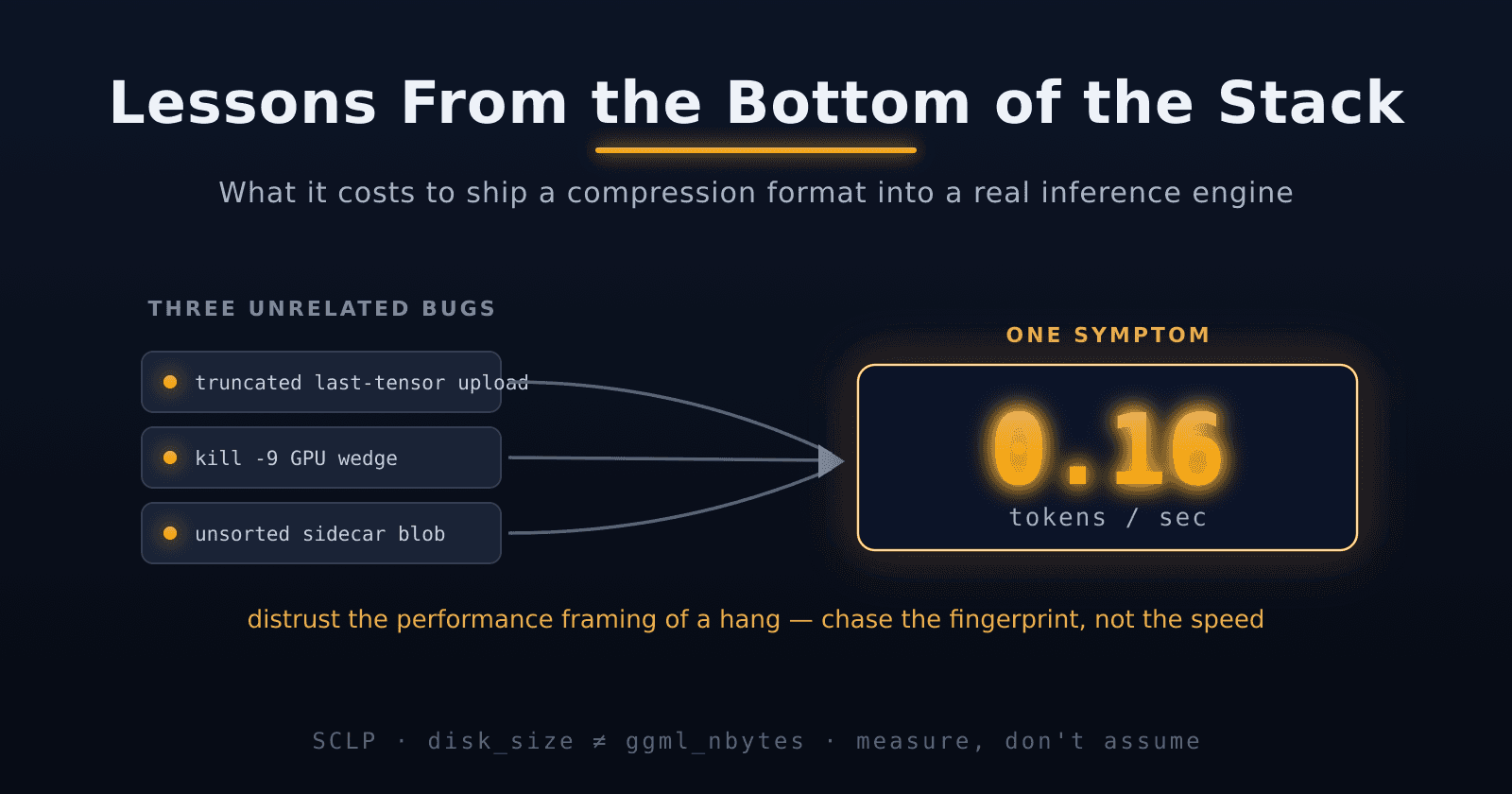
Lessons From the Bottom of the Stack: Shipping a Quant
Shipping a 4-Bit LLM Quant into llama.cpp
Jun 5, 202612 min read
Search for a command to run...
Shipping a 4-Bit LLM Quant into llama.cpp
Last time we cut BF16 weights in half by treating the exponent as a 16-entry palette instead of an 8-bit field. SCLP8: 7.9 GB instead of 15.0, perplexity slightly better than the original, token gener
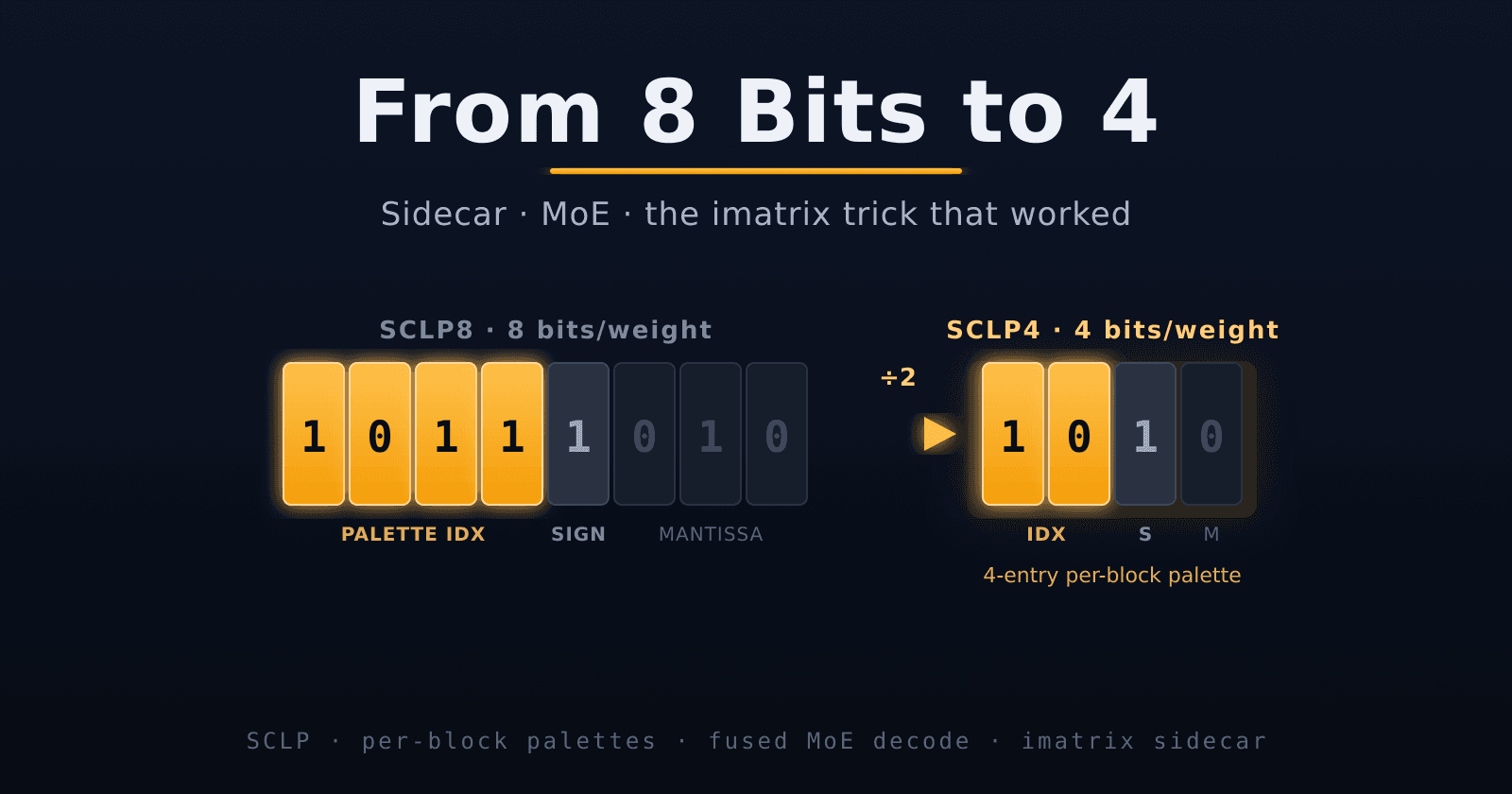
2× compression on Llama-3-8B — and perplexity went down.

Make copy of repo git clone dirtySourceRepo newSourceRepo OR clone from actual git repo and prevent push git remote set-url --push origin no_push Make sure to checkout the correct branch before the next step. Cloning from another local directory al...